

Grading AI Fluency
What it means for a Product Management organization to be fluent with AI, how to build it into the org expectations and how to accelerate your PM career for an AI future…

Hi there, it’s Adam. It has been a little while since you heard from me via this newsletter. About 6 months to be exact. I got busy, became a Webby Award Honoree for Startup Dad, lost ~30 lbs and was in a season of life that didn’t permit me the time for writing well. Publishing something that isn’t AI slop takes a lot of time and energy. I refuse to publish AI slop so I chose to take a beat on the newsletter for awhile.
Miraculously, the newsletter kept growing. I’ll understand if after a 6 month hiatus you feel the need to unsubscribe. You can do that here if you want.
But if you choose to stick around I promise it’ll be worth it. As a reminder, I started this newsletter to provide a no-bullshit, guided approach to solving some of the hardest problems for people and companies. That includes Growth, Product, and company building.
I also have a fun and educational podcast about the intersection of company-building and fatherhood. If you’re curious you can check it out above.
Now, without further ado…

Someone handed me a 47-page product requirements document a few weeks ago. It took them about 90 seconds to make. This is a real problem now. Had they read it? Nope. [Fill-in-the-blank] AI tool produced it, they put their name on top, and they forwarded it on to an engineer.
…”good luck!”
You have seen this. You may have done a version of it yourself last week. I did maybe ~6-8 months ago. And I have been stewing on this since I rolled out a set of AI fluency expectations for the product org I run at Mozilla.
How do you measure whether someone is actually good at this whole AI thing?
Most teams are measuring output and volume while patting themselves on the back about how GREAT they are at using AI for leverage.
The thing worth measuring is judgment. The thing that is easy to measure is usage. Because we often follow the path of least resistance usage becomes what everyone reaches for. It tells you almost nothing.
But it does tell you something.
Read on to learn:
Why AI usage is both a vanity metric and the right thing to measure
The four-tier rubric I put in our AI fluency guide
Why AI fluency is a banner skill that extends across levels (for now)
The blunt way to roll out AI fluency
One thing to do before anything AI-related leaves your desk
Everyone reaches for usage because it’s easy…
Walk into most companies right now and ask how they track AI adoption. You will hear about usage. Seats activated, tokens used, maybe a leaderboard with somebody’s name on top and a little fire emoji next to it. There is a whole culture forming around tokenmaxxing, where whoever runs the most queries gets treated like the most advanced person in the building.
BUT ADAM, THAT’S NOT MY ORG…
Yeah, okay, maybe not your org. Just everyone else’s.

There’s a reason that people looooove vanity metrics. And it’s the word vanity. It makes us feel good. We get to check a box and tout an accomplishment. Or maybe add another title to LinkedIn, like Tokenmaxxer Supreme.

I am going to say two things that sound contradictory. Please stay with me.
The first: usage is a vanity metric. Sort of. It is close to useless as a scoreboard. I can generate a hundred pages of confident, wrong, unread garbage faster than you can say “let’s hop on a quick call,” and on a usage dashboard I will look like a genius. Volume is the easiest thing to measure and the easiest thing to fake.
The second: early on, usage is the right thing to encourage, because usage means someone is trying, and trying is the only way anyone gets better at this. The reason I have any skill with these tools is that I have built a pile of things with them, watched the models get better underneath me, and kept poking at the edges. You cannot think your way to fluency from the sidelines.
So if your team is early, I am not going to yell about high usage or call it a useless metric. I am not going to play CFO and tell people to switch to the cheap model to save forty cents. Let them cook. Let them make a mess.
We track team-level adoption at Mozilla for exactly that reason. Claude Code sits around 75-80% daily active in engineering. Lately, it is ~85-90% in Product Management. Do I know the ceiling on either of those? I do not. Do I know how good every one of those sessions is? Sure don’t. But I know who’s in the arena trying stuff and I know we can keep working towards 100%.
Usage is the floor. It is the cost of entry, the thing that gets you in the arena. It is not how you do the job once you are inside. The moment a team is collectively past “is anyone even trying this,” usage stops telling you anything useful, and you have to ask the harder question:
When you use it, are you any good at it?
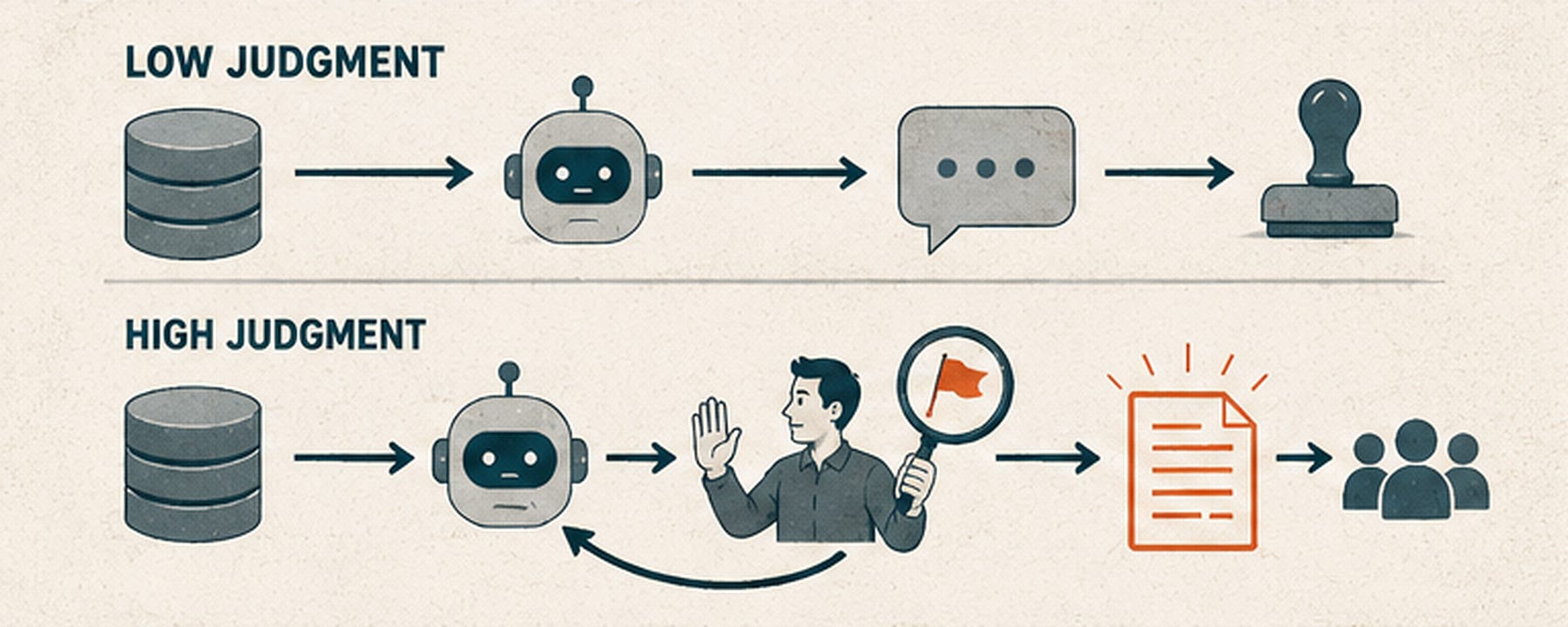
Judgment
“Judgment” is one of those words that sounds great and means nothing until you watch it happen, so let me use myself as the bad example first.
Early on, I did the lazy version. I had a pile of data and a question about it, I dropped the data into Claude, I asked it to analyze the thing, I got an answer back, and I sent that answer more or less straight to a peer of mine.
It looked productive. It took about 30 seconds. And it had an error in it that I should have caught. Someone else caught it instead, in front of exactly the people you do not want catching it.
Ouch.
But hey, let’s chalk it up as a learning opportunity. It’s why I can now describe the low-judgment path so precisely. I have walked it.
Here is that same story with judgment applied.
Same tool, same data. I drop it in, I get the analysis back, and then I actually read it. One number sounds the alarm because based on what I know, it looks off. So I push back. I tell our friend Claude that does not track, here is why, look again. It turns out I was right. It had made an error, it fixed itself (after thanking me profusely of course), and the second pass comes back… better. That second output (or the 3rd, 4th or 5th) is the thing I take to the team.
The whole difference is the time I took in the middle to notice that something was off and refuse to ship it.

Noticing is the job now. Usage is getting easier by the second. What’s separating the good from the great is the quality of a person’s skepticism.
As a brief aside… in a Maven Lightning talk I did recently with Krista Seiden at Amplitude someone asked us:
How can people with less experience know when to question AI output?
I told them to think like you’re in the dentist chair. If a dentist says to you “we need to drill four of your teeth,” you can and would ask the dentist some questions:
Can I see the mirror in my mouth that show that?
What about the x-rays?
What did these teeth look like last time?
How much will this cost and what will recovery be?
You wouldn’t just say “GO NUTS DOC. MAYBE DRILL A FEW MORE WHILE YOU’RE IN THERE.”
You’d ask those questions if you were 16, 22, 35, or 70. Seniority and experience wouldn’t matter in the dentist chair.
So… treat Claude like the dentist.
Good, Better, Best, and… Unacceptable
I stan a three-tier pricing model. So when I sat down to build the rubric for AI fluency in the product org at Mozilla I started there with “good, better, best.” Aaaaaand, I added one very small thing to the front of it: unacceptable.
I think most people are too polite to add that column. But I find it pretty useful. If someone told me I was or wasn’t doing something that was “unacceptable” that would snap me to attention.
Let’s start at the bottom. It’s the most clarifying.

Unacceptable is the person who will not touch it AI. “I don’t use it, I’m skeptical, and let me list every reason it’s flawed.” I have a soft spot for skeptics and healthy doubt is a feature, but arms-crossed refusal in 2026 is game over for product managers. And it doesn’t help anyone to pretend otherwise. The role is changing. You wouldn’t refuse to use a computer as a product manager so sitting it out is not on the menu.
Good is the baseline. You draft a doc with ChatGPT, you use it as a better search engine, you do some desk research. Fine. But look at what it actually is: you are using AI as a slightly nicer version of the tools you already had. You sped up a few tasks and you did not change how you work. Good is something. It’s just not great.
Better is where it starts to matter, because now you are building leverage that outlives a single prompt. A PM on my team got tired of hand-tagging user interviews, so she built a workflow that turns a messy folder of raw interview notes into clean, tagged theme clusters in a few minutes. Her whole pod runs on it now. That’s better. You changed how the work gets done so you could get on with driving outcomes. Another group built an operating system that takes an experiment from hypothesis to analysis end to end. That’s leverage. That’s better.
Best is more rare. Best is when you build the thing the whole company runs on. The shared research-synthesis workflow, the standard eval harness, or the context library every PM starts from. Other people’s work gets better because of something you built and shared, whether or not they ever meet you. That is best. In product management we talk a lot about influence. This is the ultimate form of influence.
Now, back to what I talked about at the onset of this newsletter. None of these tiers are about volume. Best never meant whoever made the most stuff. Every rung of this ladder expects discernment: how well you apply judgment to the output, and how you pair your own product sense with the tool to make the result genuinely better. Output quantity does not enter into it.
In stating that up front I was designing against performative AI usage. The 47-page AI-slop PRD I opened this newsletter with. I’m not trying to encourage the person who confuses motion with progress and floods the zone with documents nobody reads. You will get some of that early. It’s fine. As Andy Grove used to say: let chaos reign then rein in the chaos.
So what about leveling?
AI fluency is a really lengthy guide that summarizes nicely into the unacceptable/good/better/best. And I thought long and hard about whether it should be part of leveling (and how). Right now I think it should be but eventually leveraging AI should be like using Google Docs, JIRA, or a computer. Although eventually… two of those three might go away entirely. I’ll let you guess which two.
I also made the call not to attach AI fluency to a specific level. It’s a banner that runs across the entire IC career ladder. This is an important distinction - you can be a junior product manager who is the most impressive user of AI on the entire team and that still doesn’t make you ready for promotion. AI tools let you crank out a lot more and if used well they can give you a lot of leverage, but they won’t give you judgment. They won’t give you product sense. They won’t give you taste.

Although fluency is expected everywhere it carries you nowhere on its own. There is a lot more to the job of product management than running the tool well. It will matter even more as the shine wears off and we are all left holding the “outcomes” bag.
For what it is worth, I expect this whole section of the leveling guide to age out. In a couple of years “fluent with AI” will read as oddly in a job ladder as “fluent with email.”
But Adam, isn’t this just snobbery or senior product person gatekeeping…?
A senior person who already has judgment, telling everyone the tool is secondary, while a less experienced PM drowning in work is told that producing more, faster, somehow does not count?
I hear you.
First, there are real cases where volume is the point. If you are generating fifty subject-line variants to test, or rolling through a hundred edge cases to pressure-test a flow, raw output is exactly what you want, and judgment shows up in how you read the results, your hypotheses, etc. I am against producing a lot and shipping it sight unseen.
Second, the rubric is a map for more junior product people. The most useful thing you can do for someone early in their career is tell them where the next level is, instead of letting them believe the impressive-looking output is the thing that gets them promoted.
It is not.
There is one tiny exception to this: if your work is commoditized. Most product work is not that… so let’s move on.
How I rolled it out
If a framework lives in a slide that nobody opens… does it make a sound?
I opened with one, very blunt sentence:
The role of product management is changing and the leverage AI gives you is something you need to learn or you will become unemployable.
I was careful about the why here. I am not doing this for my benefit or the company’s convenience. I am doing it for your career. Companies are already building this into their hiring loops and will not seriously look at a candidate who has not gotten their hands dirty with AI. It is where the field is going and I would rather get you out ahead of it.
I will caveat and say that this approach doesn’t work in every company or with every org. In my experience, PMs like to know the yardstick they’re measured against and they like a good challenge. But tread lightly with your own organization and remember to meet people where they are. A smart skeptic who is convinced tends to stick around longer than one who was ordered into it.
Then I wrote the whole thing out, or rather, I dictated my thoughts and notes to Claude with a pile of examples of what counts and what does not, what is real leverage and what is slop and I had Claude organize it into something useful. Then I edited. And I re-wrote. And I edited some more.
It was too long. So I distilled it to five slides, then to a single slide, so you can engage at whatever altitude you want. The next step, which I have not built yet, is to turn it into a custom GPT you can just talk to: “here’s what I did, how would you rate it against the rubric?” Closing the loop with the tool the guide is about feels like the right way to put a bow on it.
Wrapping it all up with the fingerprint test…
If you only keep one thing from this entire newsletter, keep the fingerprint test.

Before you ship anything an AI helped you make, look at it and find the places you applied your judgment. Look for the number you questioned. The section you cut. The assumption you challenged. The framing you fixed. If you can see your fingerprint, and the outcome is clear, you have done the job. If you cannot then you are not done. You are the person from the top of this piece, four minutes in, handing someone forty-seven pages you never read.
Go leave a fingerprint.
Until next time…
Want a PDF of the full AI fluency guide I created? Reply to this email and I’ll send it to you.